How to Build an AI Clinical Decision Support Questionnaire

Here's the quiet part out loud: 1 in 10 patient encounters ends in a diagnostic error. In the US, that's 549,000 to 795,000 people killed or seriously disabled every year. A big chunk traces back to inadequate clinical assessment, and the tool most clinicians still lean on for it is a questionnaire. Paper forms that got digitized but never got intelligent. An AI clinical decision support questionnaire is supposed to fix that.
We've watched teams ship "smart intake" that's really just a PDF with checkboxes. Same questions, same order, every patient, regardless of what the chart already shows. Missed context. Redundant data entry. Worse diagnostic accuracy. More clinician burnout. That's not a product. That's a liability with a login screen.
Done right, an AI intake questionnaire reads the existing patient record before the first question, skips what's irrelevant, and hands the clinician structured clinical output instead of a score they still have to decode. Done wrong, it layers new diagnostic errors on top of the ones you were trying to solve.
This guide is for product managers, CTOs, and clinical informatics leads who want the practitioner view, not a vendor deck. You'll leave with a build blueprint: how the AI layer actually works, where the regulatory line sits, and what it takes to ship without a 6-month scratch build.
How do you build an AI clinical decision support questionnaire?
Build on top of a validated clinical instrument (PHQ-9, GAD-7, SDOH, or specialty equivalent), add an adaptive layer that pulls patient context from the EHR via FHIR R4 before the first question and branches based on real-time responses, and return a structured FHIR output (Observation or QuestionnaireResponse) that writes back to the record. To stay in the FDA's Non-Device CDS lane, design for Criterion 4 from day one: every AI-generated recommendation must show its reasoning so the clinician can independently review it.
Key Takeaways
- Adaptive beats static, but only if you build it right. A static form is a clipboard with a CSS file. An AI questionnaire that reads the EHR before the first question, branches on real responses, and writes structured output back to the record is a different species. Build it right and you get better diagnostic efficiency, lighter clinician load, and a clean signal to track patient outcomes over time. Build it carelessly and you've bolted hallucinations and regulatory exposure onto a workflow that didn't have either problem yesterday. The delta between the two is all in the engineering discipline. Pick a side.
- Explainability is the regulatory fulcrum now. The FDA's January 2026 guidance widened the Non-Device CDS lane, which is good news. But read Criterion 4 carefully: the clinician has to be able to independently review the AI's reasoning. That's where AI-enabled tools actually pass or fail. We've seen teams try to retrofit explainability in the last sprint before launch. It never works. Wire it into the architecture on day one, or plan on rewriting the thing before your first audit.
- The regulatory window is open right now. The FDA's 2026 guidance just clarified the exempt CDS lane. The EU AI Act's high-risk deadlines are closing in (August 2026 for Annex III, August 2027 for medical-device AI). FHIR Questionnaire is quietly becoming the default interoperability layer. Three tailwinds, all lined up. There hasn't been a cleaner moment to ship a well-scoped AI clinical decision support questionnaire. Windows like this don't stay open. Build now or watch someone else do it.
Static vs. Adaptive: What Actually Changes
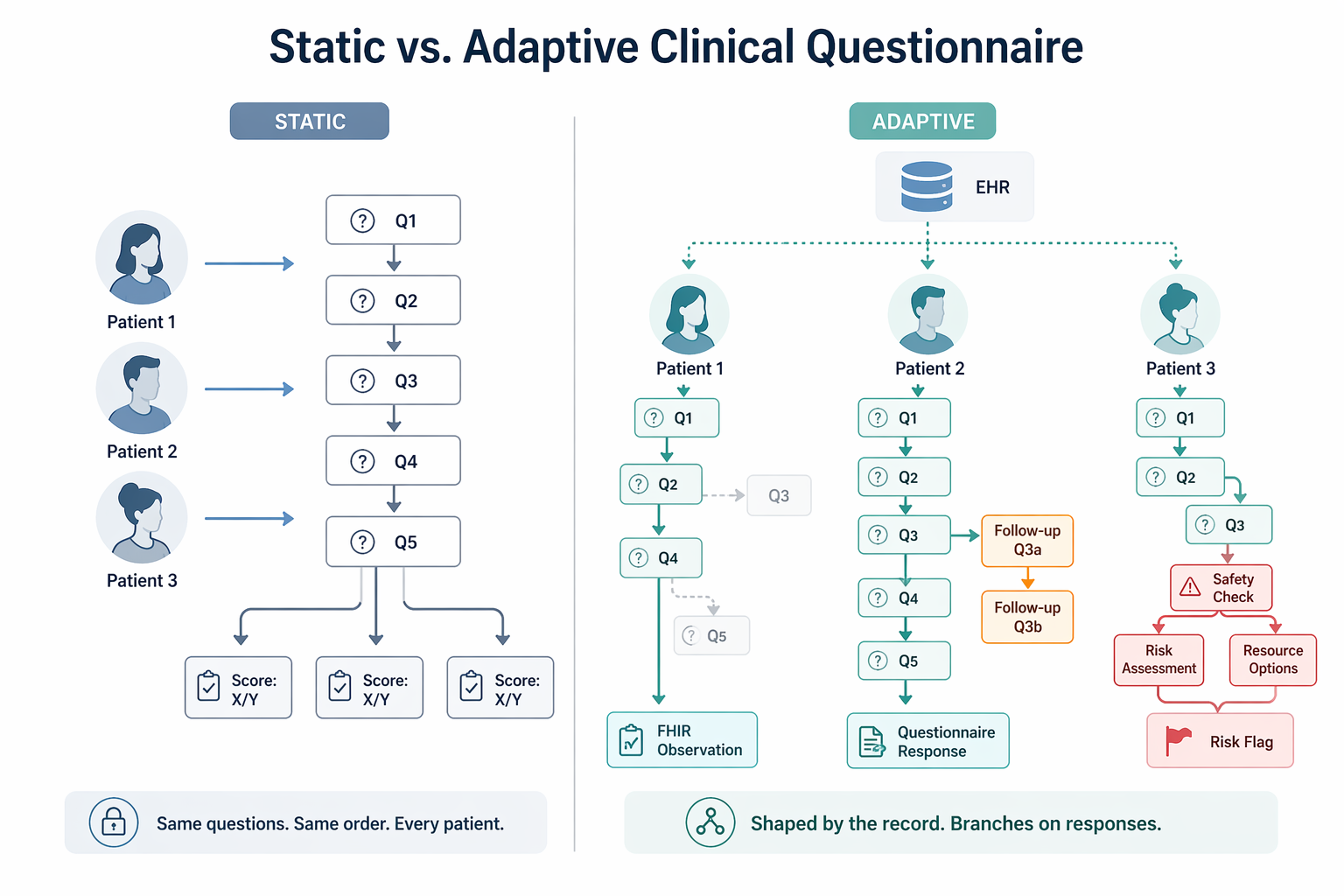
A static PHQ-9 doesn't care if the patient answered it five times this year or has never seen it before. Same nine questions, same order, every visit. An adaptive clinical questionnaire does four things a clipboard version structurally can't.
Reads the Record Before the First Question
Before a single question lands on screen, the tool pulls what's already known: diagnosis history, current medications, prior scores. That's the conditional context. The form the patient sees is already shaped by their chart, not by a template someone wrote in 2014.
Skips What's Already Answered or Clinically Irrelevant
A real adaptive questionnaire healthcare workflow won't re-ask about a chronic condition that's already in the problem list, and won't fire irrelevant follow-ups when the patient's profile rules them out. Shorter forms, less patient fatigue, cleaner data back to the record. This is the boring work, and it's where most vendors quietly give up.
Surfaces Follow-Up Probes on Threshold Crossings
Here's where adaptive logic earns the name. If a patient answers "more than half the days" to PHQ-9 question 9 (thoughts of self-harm), the conditional questions branch opens a safety assessment inline. Not on a separate form the clinician has to remember to administer. Not in a ticket someone reviews tomorrow. Right now, in the same flow.
Produces Structured Clinical Output
Not a score the clinician has to decode. A machine-readable result that writes back to the record, plugs into the rest of your clinical decision support stack, and can be reused by the next thing downstream (an AI prior authorization tool, a risk model, a care gap flag, whatever you build next). That reuse is where the ROI actually compounds.
This isn't hypothetical. Mayo Clinic integrated an AI-based mental health screening questionnaire into Epic via FHIR and reported real gains in diagnostic efficiency and clinician satisfaction.
The difference between static and adaptive isn't cosmetic. It's whether the questionnaire works for the patient in front of you, or just collects data someone has to clean up later.
Know the Regulatory Boundary Before You Build
This is where a lot of clinical decision support projects quietly die. Miscategorise the product and you're either shipping a device without clearance, or over-engineering a form for rules that never applied to you. Both are expensive. One is a lot worse.
FDA: The Four Non-Device CDS Criteria
Under Section 520(o)(1)(E) of the FD&C Act (added by the 21st Century Cures Act), a software function is excluded from the "device" definition if it meets all four:
- doesn't acquire, process, or analyze medical images or signals from an IVD
- displays or analyzes medical information about a patient
- provides condition-, disease-, or patient-specific recommendations to an HCP
- enables the HCP to independently review the basis for those recommendations
Miss one, you're a device. There's no partial credit here.
What the January 2026 FDA CDS Guidance Actually Changed
On January 6, 2026, the FDA issued revised final CDS guidance that supersedes the 2022 version. Two shifts matter for an AI clinical questionnaire. First, a new enforcement discretion policy for tools that provide a single recommendation when that recommendation is clinically appropriate. Second, the removal of 2022 language that treated risk scores and risk probabilities as automatically disqualifying.
Net effect: the low-risk CDS lane is genuinely wider than it was 12 months ago, and risk-stratification outputs are no longer an automatic dealbreaker.
The caveat for AI builders: complex or "black box" models have a harder time qualifying unless explainability is built in deep enough for a clinician to do a real independent assessment. The FDA CDS guidance makes Criterion 4 the place where AI transparency actually gets tested. Wire it in on day one, not week 38.
EU AI Act: Two Deadlines That Matter
If you're EU-facing, mark these: Annex III high-risk AI systems must comply by August 2, 2026. Annex I high-risk (including AI embedded in MDR/IVDR-regulated medical devices) by August 2, 2027. If your questionnaire qualifies as a medical device under MDR, AI Act high-risk obligations apply automatically. Build for it from day one or don't ship to the EU. Retrofitting this is not a weekend job.
HIPAA
Any questionnaire collecting identifiable patient responses is handling PHI. That means BAAs with every vendor that touches it, audit logging on every submission, and documented medical necessity for the data you collect. Non-negotiable. We've seen teams "ship a demo" here and inherit a year of breach risk.
If you don't want to build the HIPAA stack from scratch, a purpose-built HIPAA-compliant healthcare app builder handles the foundation so your team can focus on the clinical logic that actually differentiates you.
The takeaway: The January 2026 guidance genuinely widened the non-device CDS lane. Design around Criterion 4 (explainability, independent review) and do your clinical screening tool development on solid health informatics fundamentals, and an AI-enabled adaptive questionnaire can sit in that lane cleanly. Skip the fundamentals and no guidance update will save you.
Technical Architecture: Building the AI Layer
AI CDSS development lives or dies by how well six components talk to each other. Treat them as a pipeline, not a feature list. Skip one and the others don't rescue you.
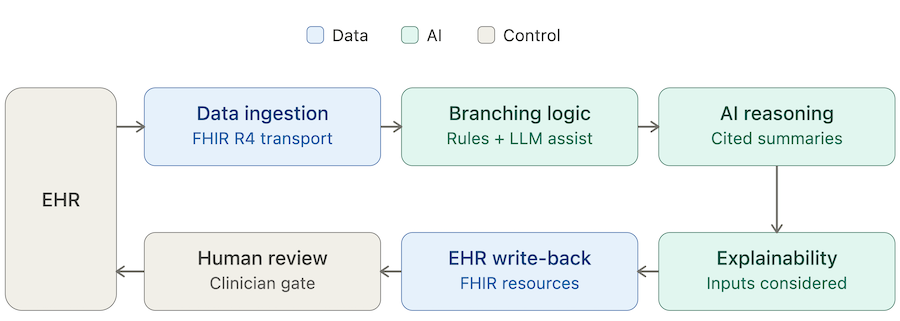
Data Ingestion Layer
Before the questionnaire opens, pull patient context from the EHR: demographics, problem list with ICD codes, current medications, prior assessment scores, recent labs. FHIR R4 is the default transport. CDS Hooks can serve as the point-of-care trigger that fires the workflow. The output of this layer is clean structured data ready to feed the reasoning layer, not raw EHR dumps your downstream model has to untangle.
Question Branching Engine
This is where the branching logic clinical questionnaire actually lives. Two design choices, and they aren't equivalent:
- Rule-based decision trees. Transparent, auditable, easier to validate clinically. The right default for any adaptive variant of a validated instrument.
- LLM-driven branching. More flexible, harder to validate, carries real hallucination risk. Useful for free-text follow-up probes. Rarely the right call for the core logic.
A defensible rule we give every client: rule-based engines for anything that contributes to a score or a risk stratification output. LLM assist only where the worst-case failure is a badly worded follow-up, not a wrong clinical flag. Get this hierarchy wrong and you'll spend your second year unwinding it.
AI Reasoning and Summarisation
Once the patient finishes, an LLM reads the responses alongside the EHR context and produces a structured clinical summary:
- risk signals
- relevant clinical guidelines
- a short narrative for the clinician
This is where natural language processing earns its keep. LLM in healthcare settings carries a design constraint that is not optional: every inference must cite the source question or EHR data point it was drawn from. Uncited outputs are a hallucination mitigation failure waiting to happen. Don't ship without citations. Seriously.
Explainability Layer
Every AI recommendation has to show its reasoning. SHAP values, attention weights, or a plain "inputs considered" list all work. The real design question isn't whether to include explainability. It's which format a busy clinician can actually parse in 10 seconds.
The evidence on whether explainability increases clinician acceptance is mixed. The floor isn't. Without it, a clinician has no basis to trust or override the output, and you lose Criterion 4. That's the whole ballgame.
Structured Output and EHR Write-Back
The completed assessment writes back to the EHR as a FHIR Observation, QuestionnaireResponse, or ClinicalImpression resource. Pick the one the receiving system actually expects, not the one that looked cleanest in your architecture diagram.
The point is closing the loop. The data is in the record, available at the next encounter, queryable for population analytics. This is what turns a questionnaire into clinical workflow automation instead of another data silo nobody queries.
Human-in-the-Loop Gate
The clinician reviews the AI output before it touches a clinical decision. Build the review UI so human oversight takes seconds, not minutes. If reviewing the output is slower than ignoring it, you've designed a bypass, not a gate. We've seen this mistake in production more than once. The fix is always a rewrite.
Validated Instruments: When to Use Them, When to Customize
Every team doing clinical decision support questionnaire development hits the same early fork: use an existing validated instrument, or build a custom one? The honest answer is almost always "both, and in that order." Teams that skip the validated instrument and go straight to custom are usually rewriting it 18 months later, with less data and more regulatory scar tissue.
Decision Framework
Key Principle
If an evidence-based clinical questionnaire already exists for your use case, use it as the foundation. A PHQ-9 adaptive questionnaire should still be a PHQ-9 underneath. SDOH questionnaire AI variants should still map cleanly to the validated SDOH screener your payers and EHR vendors already recognize. Treat AI as the thing that makes the instrument smarter at the delivery layer. It's not a license to rewrite the validated item bank because your PM thought the wording was clunky.
This matters most for teams doing preventative care platform development, where screening volumes are high and any deviation from recognised scales creates friction with primary care workflows, billing codes, and downstream clinical informatics reporting. Friction you'll pay for every day in production.
The short version: start with what's already validated. Let AI earn the right to deviate, and only where the clinical gain is documented. "We thought it'd be better" is not documentation.
FHIR Integration Patterns for CDS Questionnaires
Most clinical decision support system development projects underestimate integration. The questionnaire itself is the small part. Getting it to launch in the right place, speak the right standards, and write back cleanly is where the timeline actually slips. Three integration patterns do the heavy lifting. Ignore any of them and you'll feel it at go-live.
CDS Hooks
The HL7 standard for EHR-triggered decision support. When a clinician opens a chart, picks an order, or starts a discharge, a hook fires and your service surfaces a context-aware card right inside the EHR. The hooks that matter most for questionnaire workflows:
- patient-view for opening the chart
- order-select for a triggering order
- encounter-discharge for end-of-encounter assessments
CDS Hooks is the gold standard for point-of-care delivery for one simple reason: the prompt shows up where the clinician already is, not in a separate tab they have to remember to open. If your decision support lives behind a tab, it's not really decision support. It's a newsletter.
FHIR Questionnaire and Questionnaire Response
This is the FHIR-native way to represent a structured questionnaire and its responses. Building to the Questionnaire spec is what makes FHIR questionnaire integration portable. Any compliant EHR can render the form and store the response the same way. No bespoke adapters, no "we'll need two weeks to integrate with this customer." That's the whole interoperability pitch actually paying off.
The same spec powers Da Vinci's Documentation Templates and Rules (DTR) implementation guide, which is how payers collect structured documentation for an AI prior authorization tool or similar workflow. Translation: if you build a CDS questionnaire to the Questionnaire spec, you're already aligned with the interoperability pattern payers are moving toward under CMS-0057-F. That's a free tailwind. Take it.
SMART on FHIR
If the questionnaire is a standalone app that launches from inside the EHR rather than embedded native functionality, SMART on FHIR is the auth and context-passing layer. Epic, Oracle Health (formerly Cerner), and athenahealth all support it. It's the practical path for teams that want EHR-agnostic deployment without rebuilding per vendor.
Build vs. Assemble: Where Specode Fits
Every team that sets out to build a clinical decision support tool hits the same fork: scratch build, generic no-code, EHR-native survey tool, or a healthcare-specific AI builder. The trade-offs are real, and they show up on day one. Pretending they don't is how a 3-month build becomes a 9-month one.
Four Paths, Four Trade-offs
Where Specode Sits
The scratch path gives you full control and nothing else. Every FHIR resource, auth flow, and audit log is yours to build from zero. Great if you have a 12-month runway and a team that's done it before. Most teams don't.
The EHR-native path is fast, but it boxes you into the vendor's questionnaire module. You'll hit the ceiling the first time a PM asks for conditional logic the vendor didn't anticipate.
Generic form tools can ship a smart clinical intake form in a weekend, and fall over the moment PHI is involved. That's not a tooling problem you can patch. That's a foundation problem.
Specode is built for the teams that want the speed of a builder and the ownership of a scratch build. HIPAA-ready infrastructure comes with the production plan. Every line of code is exportable, modifiable, and deployable wherever you want. Same logic applies to adjacent categories like telehealth app development, where the build-vs-assemble question has exactly the same shape.
What you don't get is a pre-built clinical component library or a template catalog. Specode is a blank-canvas AI builder. You describe the questionnaire logic, the AI assembles the application. If you want templates, we're not the tool. If you want ownership and speed in the same contract, we probably are.
How Specode Can Help
For teams figuring out the fastest path from spec to shipped, Specode is the AI builder for healthcare apps. Here's what you actually get:
- HIPAA compliant production infrastructure. Backend hosting with BAA included on the production plan, plus the infrastructure patterns needed for secure data access and audit logging.
- EHR integration via AI prompts. Epic integration, Cerner integration, athenahealth, lab systems, pharmacy networks, and custom webhook endpoints can all be scoped case by case. Specode helps translate your workflow description into the app logic and integration architecture, instead of forcing you to wrestle with a rigid pre-built module.
- Blank-canvas AI builder. Describe the questionnaire logic in plain English (branching paths, scoring rules, EHR inputs, write-back behavior) and the AI assembles the application. No drag-and-drop. No component library to learn.
- Custom AI agents on the Custom tier. For bespoke CDS reasoning or summarization agents, the Custom plan includes dedicated agent development. Useful when your clinical logic is genuinely novel, not a rewrite of someone else's playbook.
- Full code ownership. Your branching logic and scoring algorithms are your IP. Export any time. Deploy anywhere. No lock-in clauses hiding in a schedule B.
Ready to see how this plays out in practice? Start a new project, describe your adaptive questionnaire in plain English, and watch Specode scaffold the auth, data model, and FHIR layer around it.
The fastest way to learn how to build a CDSS is to start building one. Specode gives you a working prototype to iterate on faster than a traditional sprint-based build. When you’re ready for production, the team walks you through HIPAA review and deployment. Your code, your IP, your call on where it runs.
Frequently asked questions
Not if it meets all four Cures Act criteria: no image or signal analysis, displays patient medical information, provides condition-specific recommendations to an HCP, and enables independent clinician review.
Use FHIR Observation for discrete assessment results, QuestionnaireResponse for the full structured response set, and ClinicalImpression when the output includes a clinician-facing narrative or risk summary.
Yes, and you should. Keep the validated item bank intact and let AI handle the delivery layer: EHR pre-read, adaptive branching, follow-up probes, and structured output generation.
If your tool qualifies as a medical device under MDR, AI Act high-risk obligations apply automatically. Plan for risk management, data governance, transparency, human oversight, and post-market monitoring by August 2027.
CDS Hooks triggers a context-aware card inside the EHR workflow at defined events. SMART on FHIR launches a standalone app that runs inside the EHR with authenticated context access.
The system surfaces the inputs and reasoning behind each recommendation, using SHAP values, attention weights, or a plain "inputs considered" list, so the clinician can independently verify the output before acting.