How to Build an AI Medical Scribe App: From Concept to Clinical Deployment

Ambient AI scribes saved Kaiser Permanente physicians 15,791 hours of documentation in 63 weeks. In the first head-to-head randomized trial comparing commercial products, one vendor saved 41 seconds per note, the other saved nothing. Both statements are true. Both are from 2025.
If you're considering AI medical scribe app development, as a clinician-founder, health-tech CTO, or product lead weighing build-versus-buy. The market is noisy and the claims don't line up. This guide cuts past the hype.
We cover: the 2026 tech stack (STT engines, LLMs, pricing), what training and guardrails actually look like when foundation models do most of the work, how EHR integration with Epic, Oracle Health, and athenahealth works in practice, HIPAA and FDA realities, the competitive landscape, and what it costs to build something real. No fluff. Just the decisions you actually have to make.
Q: How do you build an AI medical scribe app?
A: Building an AI medical scribe app requires four core components: a medical-grade speech-to-text engine (like Deepgram Nova-3 Medical or AWS HealthScribe), a HIPAA-eligible large language model accessed through AWS Bedrock, Azure OpenAI, or Google Vertex AI, FHIR R4 integration with the target EHR (Epic, Oracle Health, or athenahealth), and a physician-review workflow that keeps the clinician as the final signer to stay outside FDA device classification.
Key Takeaways
1. The enterprise ROI story is weaker than the valuations suggest. TPMG saved 15,791 hours across 2.5M encounters, a genuine outcome. But the first head-to-head RCT (Lukac, NEJM AI 2025) saved 41 seconds per note for the best product and zero seconds for the other. The market has moved from pilot to baseline expectation, but real execution still separates winners from demoware. Beat the Lukac benchmark clearly before you scale.
2. The hardest parts are commodities. The differentiation is above them. Medical STT, HIPAA-eligible LLMs via Bedrock/Vertex/Azure, and FHIR libraries are solved. What isn't: specialty-specific prompt engineering, hallucination guardrails against SNOMED and RxNorm, and workflow design that survives real clinic use. Build your moat there.
3. Epic just became a competitor. Epic's native AI Charting ("Art") launched February 2026. Third-party scribes whose only moat is Epic integration face real platform-squeeze pressure. Specialty depth, SMB economics, and multi-EHR portability are now the only defensible positions.
The Case for AI Medical Scribe App Development in 2026
The math on clinical documentation is brutal.
- The AMA estimates physicians would need roughly 27 hours per day to complete all recommended patient care plus administrative work.
- Primary care physicians spend about three hours daily on documentation alone.
- Nearly 21% of physicians still clock more than eight hours a week of "pajama time", after-hours EHR work that hasn't budged since 2022.
- Burnout is trending down (62.8% in 2021 to 43.2% in 2024), but the healthcare documentation burden remains the single biggest driver.
Ambient AI is the first technology to meaningfully move the needle. The Permanente Medical Group deployed an AI medical scribing platform to 7,260 Northern California physicians across 2.57 million patient encounters from October 2023 through December 2024, and saved 15,791 documentation hours. Eighty-four percent of physicians reported positive communication effects; 82% reported better work satisfaction.
The hype has a ceiling, though. The first head-to-head RCT (Lukac et al., NEJM AI, November 2025) tested Microsoft DAX Copilot and Nabla against usual care across 238 physicians and roughly 72,000 encounters. Nabla reduced time-in-note by 41 seconds. DAX showed no statistically significant time savings. Both products were used in only about 30% of visits. Stanford and UCLA trials landed in the same modest range.
The global AI medical scribe software market is projected to grow from $1.53 billion in 2025 to $5.08 billion by 2030 (27.2% CAGR). Roughly 30% of US physician practices already use some form of ambient scribe tool. The category has moved from experiment to baseline expectation.
The growth is real; so is the execution gap. The opportunity in medical scribe app development isn't racing incumbents on their terms. It's building for the specialties and workflows they underserve.
What an AI-Powered Medical Scribe App Actually Does
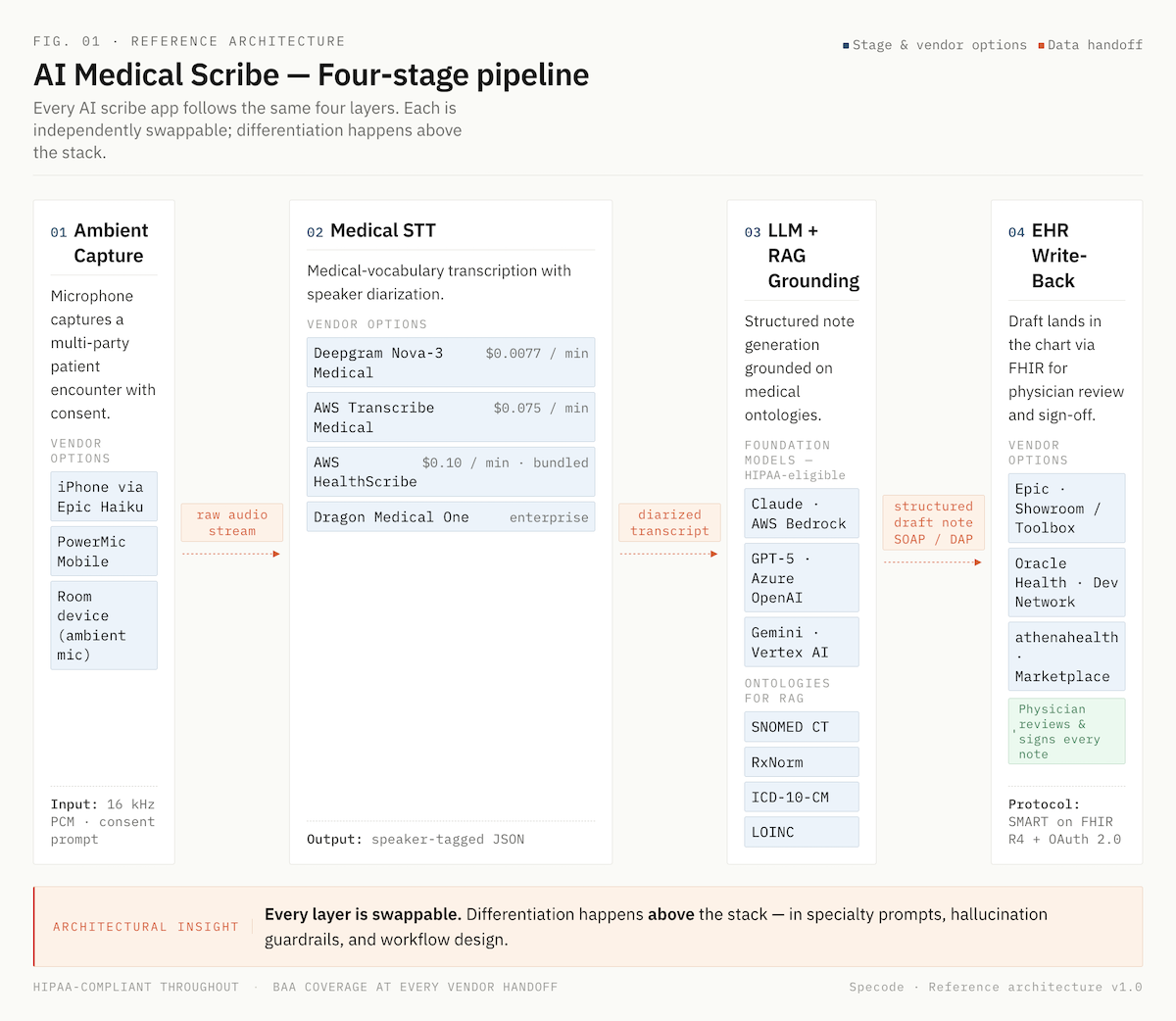
An AI-powered medical scribe app captures a clinical conversation, converts it into a structured note, and delivers it to the EHR, without the physician typing. Four stages run in sequence:
- Ambient capture. A microphone (phone, tablet, or room device) records the patient encounter with consent. No pre-scripted dictation required.
- Transcription. A medical speech recognition technology engine converts audio to text with speaker diarization, distinguishing clinician from patient.
- Structured note generation. A large language model summarizes the transcript into a SOAP, DAP, or GIRPP note, plus ICD-10 and CPT code suggestions when configured.
- EHR write-back. The draft lands in the chart via FHIR for physician review and sign-off.
Ambient scribes differ from dictation tools. Dictation requires the clinician to speak to the machine. Ambient clinical documentation apps listen to the natural patient conversation.
Technology Stack for Medical Scribe App Development
Four layers determine cost, accuracy, and compliance: speech-to-text, language model, orchestration, and EHR interface. Get these right before writing a line of product code.
Medical Speech-to-Text Engine
Generic STT fails on clinical vocabulary. Modern medical-specialized engines cluster in a tight accuracy band but spread widely on price.
Trained on 1B+ minutes annually; powers Dragon Copilot
Whisper is cheap but documented hallucination issues (fabricated medications, inserted phrases) make it unsuitable for clinical production without heavy post-processing.
Large Language Model
This is where medical language models generate the structured note from the transcript. Three HIPAA-eligible paths in 2026:
- AWS Bedrock: Claude, Meta Llama, Amazon Titan, Mistral. Covered under AWS BAA with no model-level exclusions.
- Google Vertex AI: Gemini 2.5 Pro, Gemini 2.0 Flash, Med-Gemini variants. HIPAA-eligible.
- Azure OpenAI: GPT-5 and GPT-4o for text endpoints under Microsoft's BAA.
Medical-tuned open-weights (OpenBioLLM-70B, Meditron, BioMistral) are viable for self-hosted deployments where per-token cost matters more than latency-to-market. Interesting clinician-preference signal: in MedArena testing across 12 LLMs, physicians cited depth and clarity more often than raw factual accuracy when explaining preferences. Benchmark scores alone don't predict real-world fit.
Streaming vs. Batch Architecture
Real-time streaming gives the clinician a note draft seconds after the visit ends. The UX bar is now "finished before the patient leaves the room." Batch is cheaper but relegates you to "sometime tonight" territory, which is the workflow AI scribes are supposed to replace. Build streaming first; batch as fallback.
Orchestration Layer
This is your app's logic: audio chunking, partial transcript handling, LLM prompt assembly with patient context, structured data extraction for ICD-10/CPT suggestions, and retry logic when any component fails. RAG grounding on SNOMED CT, RxNorm, and LOINC happens here.
When learning how to create AI medical scribe software that clinicians actually trust, treat each layer as independently swappable. Model landscape will change; your architecture shouldn't need to.
Core Features of an Automated Medical Scribe App
Effective AI scribe application development starts with scoping the core feature set correctly. Some capabilities are table stakes in 2026. Ship without them and clinicians abandon the tool within weeks. Others are genuine differentiators that justify premium pricing or specialty focus.
Table-Stakes Features
- Ambient listening technology captures multi-party encounters without triggering or handoffs.
- Real-time transcription with medical vocabulary training for specialty terminology, drug names, and clinical acronyms.
- Structured clinical note generation in SOAP, DAP, and GIRPP formats, configurable per specialty.
- Diagnostic coding automation with ICD-10 and CPT suggestions for physician review.
- Patient summary and action item extraction for after-visit summaries and care plans.
- Multi-speaker diarization that reliably separates clinician from patient (and family members).
- Clinical decision support touchpoints, not diagnostic recommendations but surfacing relevant guideline checks when a condition is discussed.
- Quality metrics: edit distance between draft and signed note, hallucination flags, omission detection.
Differentiators That Move the Needle
- Contextual understanding across a full encounter (not just the current utterance), so pronoun and negation errors drop.
- Specialty-specific prompts and templates for 40+ specialties, each with its own documentation conventions.
- Provider feedback loops that learn house style from signed-note edits, tightening personalization over weeks.
- Predictive auto-completion inside the EHR for repetitive fields.
- Risk stratification alerts for flagged findings (with physician sign-off preserved).
- Integration with clinical guideline databases and institutional protocols.
UX Design for Clinical Documentation Apps
Clinicians abandon scribe tools that add friction. Good UX for a voice-to-text medical app is measured in taps, not features. Every extra interaction erodes the physician workflow optimization gains the technology promises.
One-Tap Capture
The clinician starts recording in a single action from the patient's open chart, no app switching, no manual selection. Patient encounter documentation context pulls from the EHR automatically.
Voice Commands for Structure, Not Dictation
The point of ambient capture is to free the clinician from talking to a machine. But voice commands like "format HPI as bullets" or "add follow-up in six weeks" let them shape the note without a keyboard.
Mobile-First, Desktop-Equivalent
Most capture happens on iPhone via Epic Haiku or PowerMic Mobile. Desktop parity matters for editing. A draft started on mobile must be editable on desktop without losing formatting or real-time transcription accuracy.
Review Before Sign-Off
Drafts should land in the EHR within 60 seconds of visit end, with visual markers for uncertain segments. Clinical notes automation without physician review breaks medical record accuracy.
Training and Adapting AI Models
Nobody trains clinical foundation models from scratch in 2026. The build-versus-buy decision collapsed into a narrower question: which frontier or medical open-weight model do you adapt, and how? The real engineering work has moved up the stack, to prompting, retrieval, fine-tuning, and guardrails.
Model Selection
Two credible paths:
- Frontier models via HIPAA-compliant clouds (Claude, GPT-5, Gemini): best general reasoning for note generation; fastest time-to-market.
- Medical-tuned open-weights (OpenBioLLM-70B, Meditron, BioMistral): viable when self-hosting economics or data residency matter more than latency. OpenBioLLM-70B outperforms GPT-4 on some biomedical benchmarks.
Clinician preference data from MedArena cuts through the benchmark noise: physicians cited depth and clarity more often than raw accuracy when choosing between models.
Prompt Engineering and Fine-Tuning
A generic "write a SOAP note" prompt produces generic output. What actually moves quality:
- Structured system prompts with specialty-specific templates and institutional style guides.
- Few-shot examples drawn from signed notes.
- LoRA or PEFT fine-tuning for deeper personalization without retraining weights from scratch.
RAG Grounding
Retrieval-augmented generation against medical ontologies (SNOMED CT, RxNorm, LOINC, ICD-10-CM) catches hallucinations before they reach the note. Let the model cite, not invent.
Hallucination Guardrails
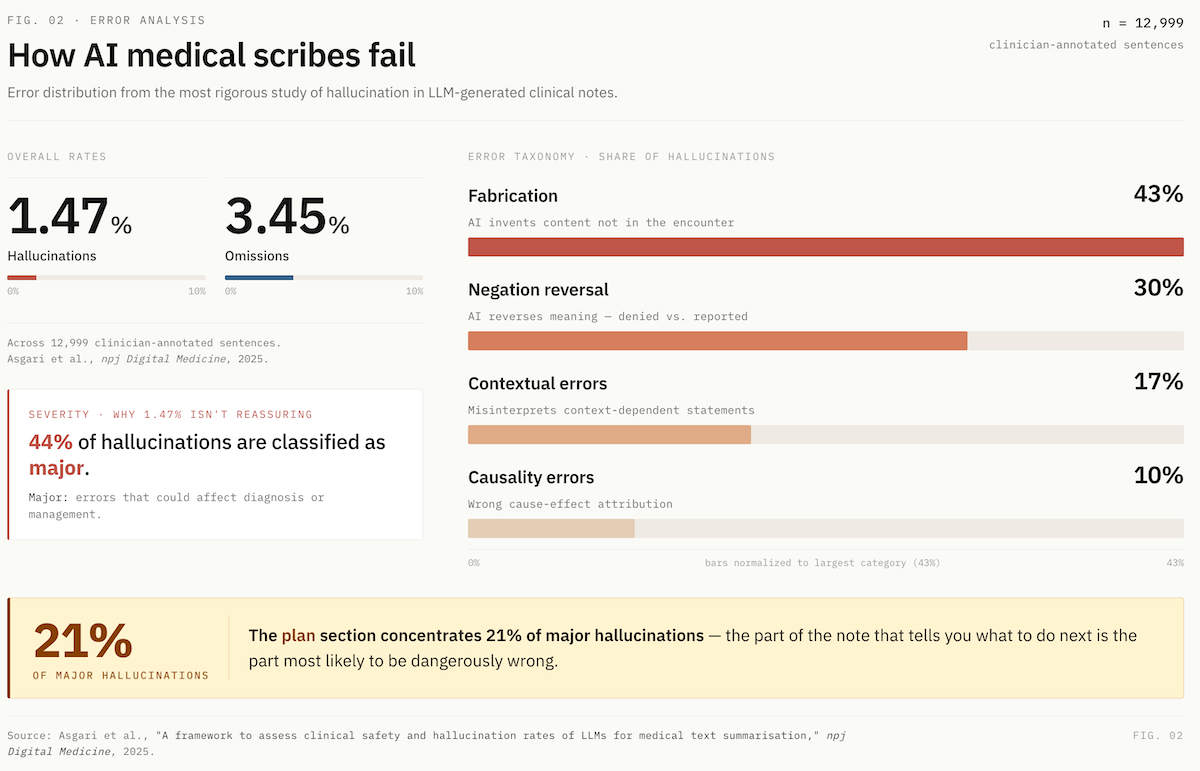
The published rates are sobering. The most rigorous study to date (Asgari et al., npj Digital Medicine, 2025) found:
- 1.47% hallucination rate and 3.45% omission rate across 12,999 clinician-annotated sentences.
- 44% of hallucinations classified as major, meaning errors that could affect diagnosis or management.
- Error taxonomy: 43% fabrication, 30% negation reversal, 17% contextual, 10% causality.
- The plan section concentrated the highest rate of major hallucinations (21%).
A separate study found 31% of AI-generated notes contained hallucinations versus 20% of physician-authored notes.
The Architectural Response:
- Entity verification against a medical terminology database (SNOMED, RxNorm) to flag fabricated drugs or diagnoses.
- Negation detection to catch reversed meanings.
- Confidence scoring on clinical assertions, with visual flags in the UI.
- Mandatory physician review, especially on the plan section.
- AI training datasets for reinforcement should come from signed-note deltas, not unverified clinician feedback.
Treat every flagged segment as a labeling opportunity for continuous clinical documentation improvement. This is what separates real intelligent medical documentation from a demo that crumbles in production: deep learning models generate fluent prose, but only disciplined retrieval, grounding, and human review produce notes clinicians will sign.
EHR Integration and Healthcare Interoperability
When you develop AI medical scribe software in 2026, electronic health records integration is where most build timelines slip. The standards have stabilized, but the politics around them haven't, and the platform landscape just shifted dramatically.
FHIR R4 Is the Baseline
All three dominant EHRs (Epic, Oracle Health or formerly Cerner, and athenahealth) support SMART on FHIR with OAuth2. R5 is emerging but R4 remains the practical target for write-back integrations. Read operations that matter for a scribe app: Patient, Encounter, Condition, MedicationStatement, Observation, AllergyIntolerance. Write operations: DocumentReference for the note itself, plus structured resources when supported.
Epic Just Became a Competitor
In February 2026, Epic launched native AI Charting under its "Art" platform, built in partnership with Microsoft. It's not a passive scribe; it queues orders from conversation, restructures notes via voice commands, and draws on the full patient record natively. Third-party scribes whose only moat is "we integrate with Epic" face real platform-squeeze risk.
Epic Marketplace Terminology
- App Orchard → renamed Epic Showroom.
- Toolbox: curated category within Showroom; Ambience, Suki, and Commure are current AI scribe members, following shared medical documentation standards.
- Partners and Pals: deeper tier; Abridge holds first "Pal" status for generative AI charting.
Oracle Health and athenahealth
Oracle rolled out an AI-backed EHR with voice commands in 2025 and was designated a QHIN under TEFCA in November. Developer integration runs through the Oracle Health Developer Network. athenahealth publishes AI features via athenaMarketplace on the same SMART on FHIR foundation, friendlier onboarding for SMB-focused builders.
ONC Rule State (April 2026):
- HTI-1 Final (Jan 2024): in effect; USCDI v3 compliance deadline was January 1, 2026; algorithm transparency required for certified health IT with predictive features.
- HTI-2 Final (Dec 2024): TEFCA, QHIN designations, Manner Exception for info blocking.
- HTI-4 Final (Aug 2025): e-prescribing, real-time prescription benefit, electronic prior auth.
- ASTP/ONC Deregulatory Actions NPRM (Dec 2025): proposed streamlining of certification requirements. Documentation compliance expectations are shifting toward API-focused modularity, less prescriptive EHR-functionality gating.
Build Pattern That Works
Start with one EHR and one specialty. Use SMART on FHIR for launch context so the clinician never manually selects a patient. Write drafts to DocumentReference in a "pending review" state, never auto-sign.
For healthcare interoperability beyond a single EHR, abstract your integration layer early so adding Oracle or athenahealth later is an adapter swap, not a rewrite. Strong API integration capabilities are what separate a portable healthcare AI application from a vendor-locked one.
HIPAA Compliance for AI Medical Scribing Platforms
HIPAA basics are table stakes, encryption, access controls, audit logging, minimum necessary, signed BAAs with every subprocessor. Any team shipping an automated medical scribe app in 2026 has these on day one. Real complexity lives in three places that trip up even experienced builders.
The foundation-model BAA chain is more tangled than it looks.
- Direct APIs cover PHI, but through different doors. OpenAI signs API BAAs, but only zero-data-retention endpoints are covered. Anthropic's API BAA is sales-assisted via inquiry form, covering HIPAA-ready services plus its new HIPAA-ready Enterprise plan (launched December 2025). Both vendors now offer dedicated healthcare tiers (ChatGPT for Healthcare, Claude for Healthcare). Never covered: ChatGPT Free/Plus/Pro/Team/Business (yes, Business is excluded too), Claude Free/Pro/Max/Team, Anthropic's Workbench and Console, Claude.ai, and Gemini consumer apps.
- Cloud-based medical AI is often the cleaner path. AWS Bedrock covers all hosted models (Claude, Llama, Mistral, Titan) under the AWS BAA with no model-level exclusions, and model providers cannot see inputs or outputs. Google Vertex AI covers Gemini 1.5 Pro and Flash (NotebookLM excluded). Azure OpenAI covers GPT-5 and GPT-4o text endpoints (GitHub Copilot excluded).
- Anthropic is currently the only major foundation model HIPAA-eligible through all three clouds (Bedrock, Vertex, Azure): a rare point of architectural portability if cloud lock-in is a concern.
Non-obvious gotchas: Azure OpenAI covers text endpoints, not all modalities. OpenAI's Regulated Workspace lists Codex and multi-step Agent as "Non-Included Functionality", off-limits for PHI even with a BAA. Cloud-provider model availability lags direct API by 1–8 weeks, relevant if you need the latest model.
The Security Rule Update Is Imminent
The HIPAA Security Rule NPRM was published January 2025; the final rule is on OCR's regulatory agenda for May 2026, with an expected 240-day compliance window. Likely mandates:
- MFA across all ePHI access points (no exceptions).
- Encryption in transit and at rest (no "addressable" fallback).
- Annual risk assessments plus annual compliance audits.
- Asset inventory and network map, updated annually.
- 72-hour incident response and restoration.
- Biannual vulnerability scans, annual penetration testing.
Build for the Coming Rule, Not the Current One
Build for the coming rule, not the current one. Retrofitting MFA, encryption audits, and formal incident response into a live scribe platform is painful. Architect HIPAA compliant AI and scalable healthcare solutions now. Approach this as HIPAA compliant development from day one rather than a bolt-on, and the May 2026 finalization is a paperwork exercise, not a rebuild. Strong healthcare data security becomes a trust signal with enterprise buyers, not a compliance tax.
FDA and Regulatory Considerations
Most AI medical scribes stay outside FDA device classification by design. The path runs through the 21st Century Cures Act non-device CDS exemption, and it got more permissive in January 2026.
The four non-device CDS criteria:
- Not processing medical images, signals, or patterns.
- Displaying or analyzing medical information about a patient.
- Providing recommendations to an HCP about prevention, diagnosis, or treatment.
- Enabling the HCP to independently review the basis for recommendations, so the HCP isn't primarily relying on the AI.
The January 2026 CDS final guidance made two changes worth noting. First, enforcement discretion now applies to single-output software where only one clinically appropriate directive exists, previously, only list-of-options outputs qualified. Second, risk scores can now fall under the exemption, reversing the 2022 blanket exclusion. Clinical workflow automation that surfaces a single coding suggestion or risk flag has breathing room.
Where scribes cross into device territory: clinical alerts that bypass physician review, diagnostic directives without transparent reasoning, automated order entry, or time-critical real-time clinical insights affecting immediate treatment.
For iterative AI updates, the FDA's December 2024 final PCCP guidance lets you pre-authorize specific updates at initial submission, covering changes to machine learning algorithms, input sources, and neural network architecture without new submissions per iteration.
FDA has authorized 1,250+ AI-enabled devices as of July 2025. Most scribes aren't among them, and shouldn't be. Keep the physician as the signer. Maintain transparent reasoning. Medical coding accuracy stays a suggestion, not a directive. That's how transcription error reduction gains don't become regulatory liabilities.
Competitive Landscape: Leading Medical Scribe AI Applications
The AI medical scribe market, one of the fastest-maturing categories among AI healthcare applications, split into three tiers by mid-2025, and a fourth dynamic, platform consolidation, is reshaping all of them.
Enterprise Tier (health systems with 1,000+ clinicians)
- Microsoft Dragon Copilot (unified from DAX Copilot + Dragon Medical One): 3M+ ambient conversations across 600 organizations per month as of March 2025; ~77% of US hospitals have some Nuance/Dragon footprint. Epic-embedded via partnership; extensive specialty templates.
- Abridge: $5.3B valuation after June 2025 Series E ($300M led by a16z), additional $316M raise April 2026. 150+ health systems including Johns Hopkins (6,700 clinicians), Mayo Clinic (2,000+), Kaiser Permanente. $117M contracted ARR Q1 2025. First "Pal" for generative AI charting in Epic.
- Ambience Healthcare: $1.25B valuation (Series C, July 2025). Cleveland Clinic five-year deal. 80+ specialty adaptations with real-time in-workflow prompts.
SMB and Clinician-Direct Tier
- Suki AI: $70M Series D (Oct 2024); 400+ health systems; $299–$399/month. Voice-first design plus Suki Platform SDK for OEMs.
- DeepScribe: Ochsner enterprise deal (4,700 physicians, 75% adoption). Strong in oncology (4M visits annually).
- Heidi Health: $99/month; 23 languages; HIPAA + GDPR.
- Freed: $99/month; $13M ARR with four salespeople, brutal capital efficiency. No deep EHR integration; targets solo practitioners.
- Nabla: The vendor that saved 41 seconds per note in the Lukac RCT. TPMG's original pilot partner.
Infrastructure Layer (for builders)
AWS HealthScribe ($0.10/min bundled pipeline), Deepgram Nova-3 Medical, Suki Platform SDK, building blocks for teams who want to own the product surface.
The Platform Squeeze
In February 2026, Epic launched native AI Charting ("Art") in partnership with Microsoft. It's not passive scribing. Art queues orders, restructures notes via voice commands, and draws on the full patient record. Third-party scribes whose only moat is Epic integration face real platform-squeeze pressure. Microsoft-Nuance remains dominant. Commure acquired Augmedix for $139M. Expect more consolidation.
The opening for new entrants isn't competing on physician burnout reduction at the enterprise level, it's specialty depth, SMB economics, and healthcare productivity tools the incumbents ignore, with clinical quality metrics that prove the workflow fit.
Development Timeline, Team, and Cost to Build a Medical Documentation App
The economics of building AI medical scribes have collapsed. What cost $300K–$500K and 9–12 months in 2022 now costs a fraction of that and ships in weeks. Because the hardest parts (STT, LLM, FHIR libraries) are commodities.
Traditional Agency Approach
The old path: hire a 5–7 person team (AI engineer, backend, frontend, healthcare domain expert, compliance specialist, PM, QA), spend 6–12 months to MVP, burn $200K–$500K before a single clinician tests the product. Then face ongoing cloud infrastructure costs, annual compliance audits (~$30K–$80K), and continuous model fine-tuning.
AI-First Builder Approach
Platforms like Specode start at $1K/month on the Pro plan, which includes HIPAA-compliant production hosting, backend BAA, and a built-in compliance agent that scans your codebase for violations. The $5K/month Custom plan adds managed coding and dedicated team support for multi-specialty scale. You describe the medical transcription software in plain English; the AI generates the frontend, data models, workflows, and integrations
A solo clinician-founder can create a medical transcription app and run a 10-physician pilot in weeks, not quarters, with provider efficiency metrics instrumented from day one.
Team You Actually Need in 2026
- One full-stack engineer who understands LLM orchestration.
- One clinician advisor (part-time) for specialty vocabulary and workflow validation.
- Fractional compliance support for BAA chain and security docs.
Pricing Models that Work
- Per-provider: $99–$400/month (Freed, Heidi, Suki ranges).
- Per-encounter: $1–$3 per visit for variable-volume buyers.
- Enterprise: $2,000–$3,000/clinician/year (Abridge benchmark).
Pilot Design
Ten physicians, one specialty, 30 days. Track edit distance, pajama time reduction, and patient interaction analysis (screen time vs. eye contact). The Lukac RCT benchmark is 41 seconds saved per note. Beat it before you scale. Conversation intelligence and automated medical summarization are where real differentiation shows, not in feature lists.
Testing and Clinical Validation
AI medical assistant app development without rigorous validation is how scribe startups quietly disappear. The industry converged on a shared rollout pattern in 2025, built on evidence from real deployments, not vendor benchmarks.
The Shadow-Mode Rollout Sequence:
- Voluntary opt-in pilot with 50–100 physicians across one specialty.
- Parallel documentation, physician types notes while AI drafts in shadow; compare outputs for two weeks.
- Physician sign-off required before any note commits to the chart.
- Formal safety surveillance flags quality issues (TPMG did this for its 7,260-physician rollout).
- Specialty-by-specialty expansion, primary care first, then procedural specialties.
Accuracy Metrics That Actually Matter:
- Edit distance between AI draft and final signed note, the most honest measure of a medical scribe AI application's real quality.
- Hallucination rate and omission rate, scored against the Asgari taxonomy.
- Pajama time reduction, time-in-notes per appointment.
- Physician satisfaction (AMA Mini Z) and patient eye-contact reports.
Benchmarks From Real Deployments
TPMG saved 15,791 hours across 2.5M encounters. Ochsner hit 75% clinician adoption in the initial DeepScribe launch, one nephrologist cut 2–3 hours of daily documentation to 3–4 minutes per note. The Lukac RCT saved 41 seconds per note for the best product.
Natural language processing has commoditized since medical dictation software and early voice-to-text conversion tools, but clinical validation has not. Beat the Lukac benchmark clearly before scaling.
How to Create an AI Medical Scribe App with Specode
Specode is an AI-powered healthcare application builder. You describe your app in plain English and the AI generates it on a HIPAA-ready foundation. The same healthcare platform development approach used for telehealth, patient portals, or specialty clinic platforms applies to scribes. It's not a pre-built scribe template. That's the point.
For a clinician-founder or health-tech team building a scribe, Specode handles the parts that don't differentiate your product, HIPAA-compliant hosting, backend BAA, authentication patterns, data models, EHR integration scaffolding, a built-in compliance agent that scans your codebase for violations. You stay focused on what does differentiate:
- specialty workflows
- prompt engineering against your chosen LLM
- the STT engine you pick
- the clinical validation that earns physician trust
Pro starts at $1K/month with production deployment included. Custom adds managed coding and dedicated support at $5K/month. Code export is unlimited, no lock-in. If you're ready to build a medical documentation app without spending six months on infrastructure, the infrastructure is already built.
Frequently asked questions
Best-in-class medical STT hits 3.44% word error rate. Aim for under 5% WER and under 2% hallucination rate, scored against the Asgari taxonomy.
Epic or athenahealth via SMART on FHIR: 4–8 weeks for read-only launch context and DocumentReference write-back. Full bi-directional integration with orders and structured data: 3–6 months.
Staying non-device under FDA's CDS exemption (physician signs every note), HIPAA compliance including the May 2026 Security Rule update, and BAA chain coverage across every subprocessor touching PHI.
Zero for foundation models, you adapt existing ones. For specialty fine-tuning via LoRA or PEFT, 500–5,000 signed note examples per specialty typically suffice. Quality over volume.
Dictation requires the clinician to speak to the machine in structured phrases. Ambient scribes passively capture the natural patient conversation and generate the note, no dictation required.
Yes, via specialty-specific prompts, Keyterm Prompting (Deepgram supports 100 custom terms), and RAG grounding on SNOMED CT, RxNorm, and ICD-10-CM. Ambience claims 80+ specialty adaptations.
STT at $0.0077–$0.10/min, LLM inference, cloud hosting, annual compliance audits ($30K–$80K), penetration testing, and continuous fine-tuning. Budget 30–40% of build cost annually for ongoing operations.
Signed BAAs with every subprocessor, encryption in transit and at rest, MFA on all PHI access, audit logging, stateless STT where possible, and no training on customer PHI without explicit consent.